How does AI affect U.S. Employment? Replicating Harvard Business School Research with NeuGBI

TL;DR
We used NeuGBI to replicate the Harvard Business School paper Generative AI as Seniority-Biased Technological Change: same Revelio Lab U.S. employment dataset (300 million records), same research question — AI’s impact on jobs. The entire analysis was conducted autonomously by NeuGBI using its built-in analytical Skills, with no human intervention. The result matched the paper’s conclusion: junior position records declined by 29.4%, while senior positions only declined by 5.8%. On some dimensions, NeuGBI went finer than the original paper — for example, within software development roles, it’s specifically junior-level (L2) positions that nearly halved, while entry-level (L1) and senior (L3+) positions showed minimal decline.
A recent Harvard Business School paper, Generative AI as Seniority-Biased Technological Change, specifically studied this question: AI’s impact on employment is not evenly distributed — junior positions are hit more significantly, while senior positions have remained relatively stable in employment volume.
The paper uses Revelio Lab employment data (hereafter “Revelio data”). Revelio classifies positions into seniority levels L1–L7 (per the Harvard paper’s definitions): Entry, Junior, Specialist, Manager, Director, Executive, and C-Suite. The paper defines “junior positions” as Entry and Junior (L1–L2), and “senior positions” as L3 and above.
This kind of open-ended question is genuinely interesting — but does answering it really require an elite research team like Harvard’s? With the advancement of large language models, a natural thought arises: let LLMs handle this kind of open-ended exploration. They can understand natural language, generate code, and interpret results — seemingly well-suited for this type of layer-by-layer drill-down analysis.
Where Current LLM-Based Analytics Fall Short
But directly feeding Revelio data to an LLM clearly won’t work: 60GB, 300 million records — far exceeding any model’s context window. Even stepping back to keep the data in a database and use an LLM-driven text-to-SQL approach (similar to chatBI) runs into three unavoidable problems:
- Data relationships are too complex. Employment data is inherently graph-structured — people, positions, companies, and skills form multi-hop relationships that are either awkward to model in SQL or prohibitively expensive to join.
- Interactive latency is unacceptable. Exploratory analysis depends heavily on instant feedback loops (“see result → refine question → query again”), but at 300 million rows, traditional databases either can’t handle it or are too slow to maintain flow. No matter how fast the LLM is, it can’t save a slow query.
- Analysis chains break. Each decomposition step depends on findings from the previous one, but text-to-SQL treats each query as an isolated task — context from earlier rounds is completely lost, preventing the LLM from truly “drilling down continuously.”
To address these pain points, we designed NeuGBI: the underlying NeuG graph database natively supports multi-hop relationships; the query layer uses end-to-end unbiased sampling so complex queries return in seconds; and the analysis model is built on Hypergraph reconstruction, naturally suited for continuous analysis and intermediate result reuse. On top of this, we packaged exploratory analysis Skills for LLMs to invoke, enabling them to autonomously conduct open-ended exploration on massive, complex data — decomposing questions, driving the engine, reading results, and deciding where to dig next.
Enough talk — let’s validate directly. Next, we’ll run NeuGBI on the Revelio dataset through the complete replication workflow and see whether its conclusions match the Harvard paper.
NeuGBI’s Query Logic
Now that we know why NeuGBI is needed, let’s look at how it decomposes this task step by step. The given question is: “How hard has AI hit U.S. employment?”
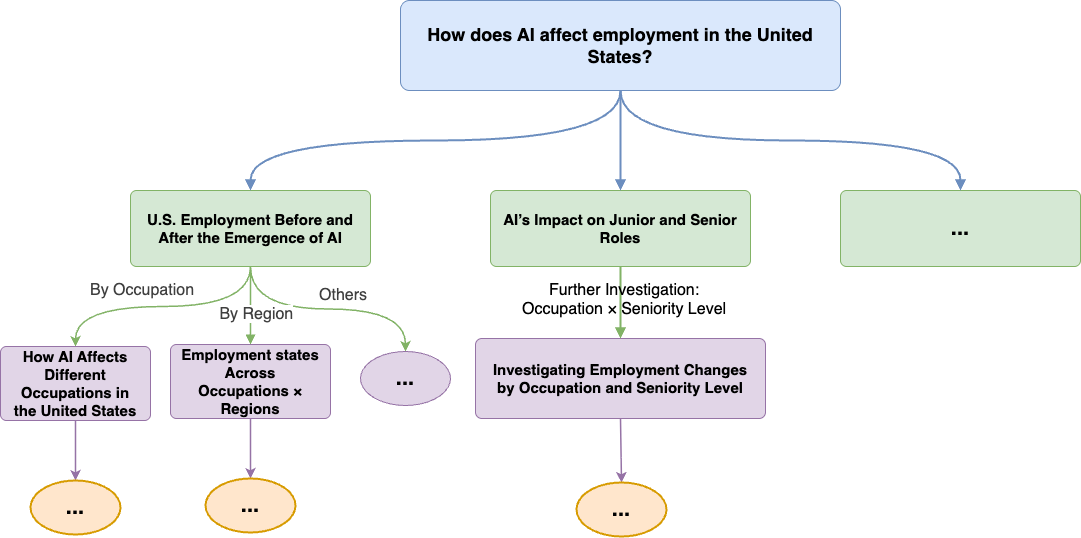
Faced with this question, NeuGBI doesn’t produce a simple conclusion. Instead, it first breaks it into queryable data problems — for example, whether overall U.S. employment changed before and after AI’s emergence; whether changes differ across occupations and regions; whether junior and senior positions changed differently. Here we examine two core analysis threads.
The first thread: examine AI’s impact on U.S. employment before and after its emergence. After observing the overall decline, continue examining different occupations and different states.
The second thread follows the Harvard paper’s main thesis: if junior positions declined significantly more than senior positions, continue drilling into different occupations and seniority levels to see exactly which category within junior positions is declining.
Exploratory analysis works exactly this way: see the previous round’s results, then decide what to query next.
1. U.S. Employment Before and After AI
First, NeuGBI queried U.S. employment conditions before and after AI’s emergence.
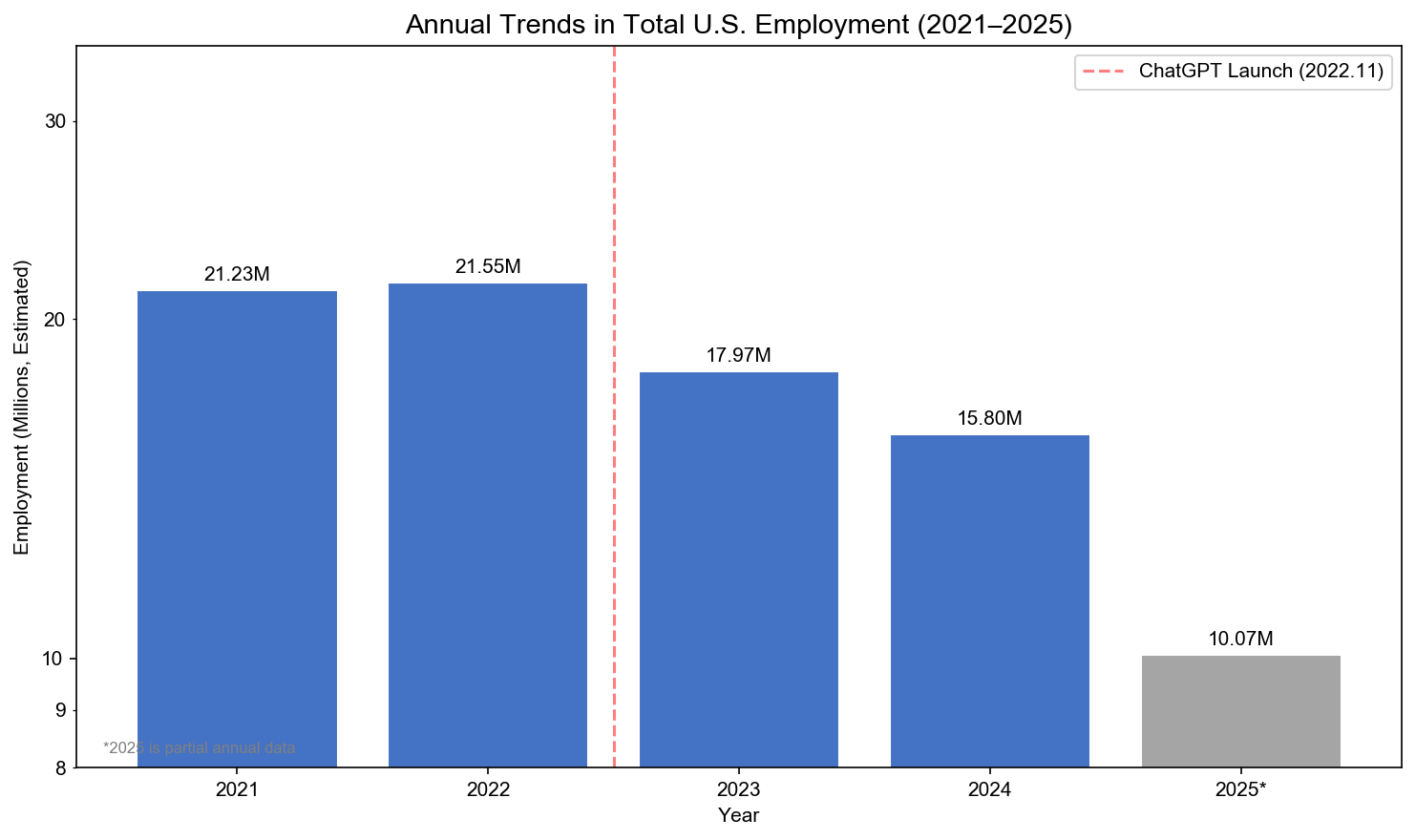
From 2021 to 2025, total employment records dropped from 21 million to approximately 10 million. Since Revelio’s coverage fluctuates over time, absolute numbers cannot be directly equated with real employment figures, but this trend tells us one thing: the data clearly shows significant contraction.
Just looking at overall U.S. employment trends isn’t enough — we don’t yet know which occupations the decline is concentrated in. So the next step: NeuGBI continues down the occupation path.
1.1 Impact on Different Industries

Due to space constraints, here we show AI’s impact on computer-related occupations (e.g., software development, systems engineering, web development). Computer-related hiring headcount declined 31% from 2022 to 2024 (2025 data is incomplete), while job posting volume declined 64%.
This data shows that U.S. computer-related hiring is declining overall, but we don’t yet know whether this decline is concentrated in just a few regions. So the next step: NeuGBI examines different states.
1.2 State-Level Breakdown

Here NeuGBI explored computer-related employment across different U.S. states. The chart shows the major states by hiring volume — most states’ computer-related hiring is declining. This indicates the decline isn’t isolated to one state but appears as a similar trend across multiple major states.
At this point, NeuGBI has analyzed AI’s impact on U.S. employment from both occupation and regional perspectives. But the results are still insufficient, so next NeuGBI pursues another path: is AI’s impact different for junior vs. senior positions?
2. AI’s Impact on Junior vs. Senior Positions
In this step, NeuGBI analyzed AI’s impact on junior and senior positions.
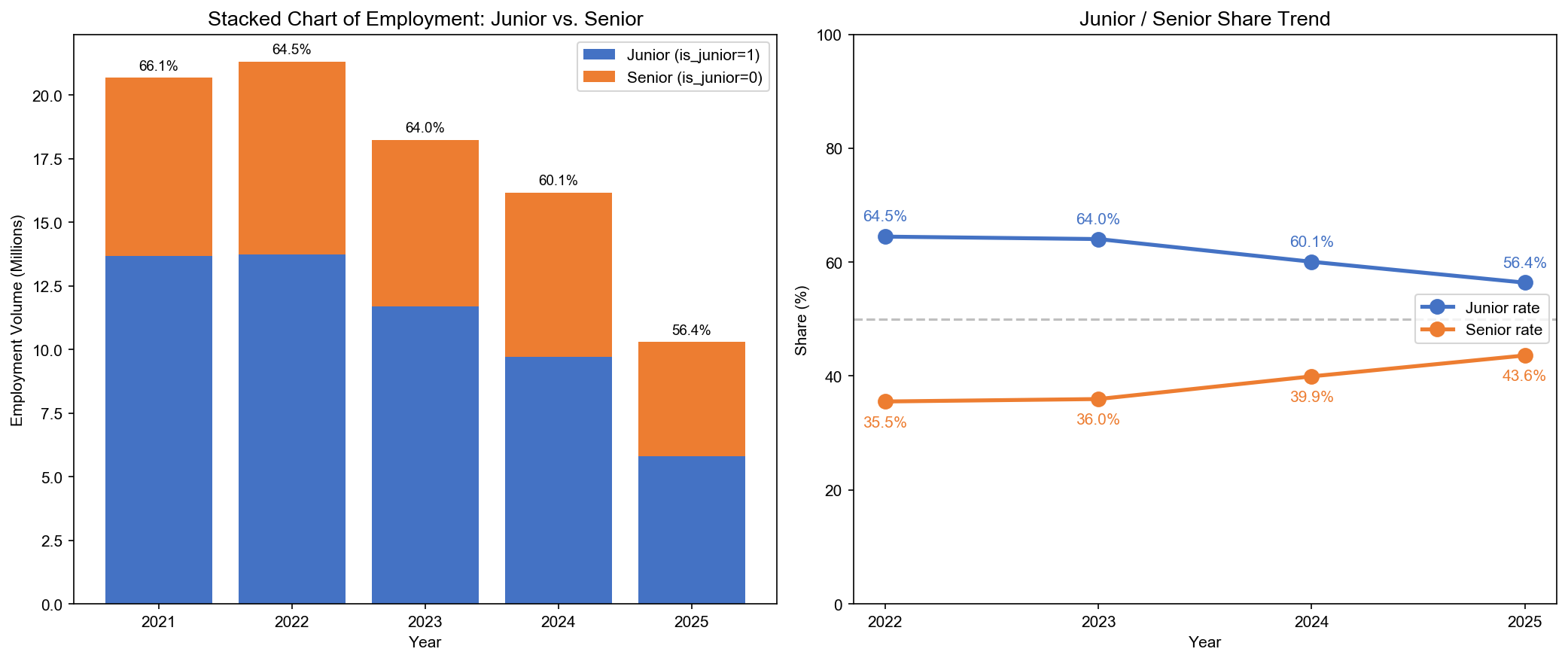
The results show that not every category declined equally. By record count, junior positions declined by 29.4%, while senior positions only declined by 5.8%. In other words, looking at share of total employment, senior positions actually rose from 35% in 2022 to 43.6% in 2025. This isn’t because senior positions grew — it’s because junior positions fell so much more, making senior positions’ share appear higher.
This result is consistent with the Harvard paper’s conclusion: junior positions contracted more significantly, while senior positions remained relatively stable.
But this answer isn’t granular enough. Junior positions themselves include both entry-level and junior-level. The data here only shows “junior positions are declining” but cannot tell us exactly which category is declining.
So here NeuGBI chose to continue drilling down, examining whether different seniority levels within specific occupations also show different patterns.
2.1 Drilling Deeper: Which Seniority Level Declined More in Software Development?
Here NeuGBI continued querying to see AI’s impact on different occupations and seniority levels. We focus primarily on software development.
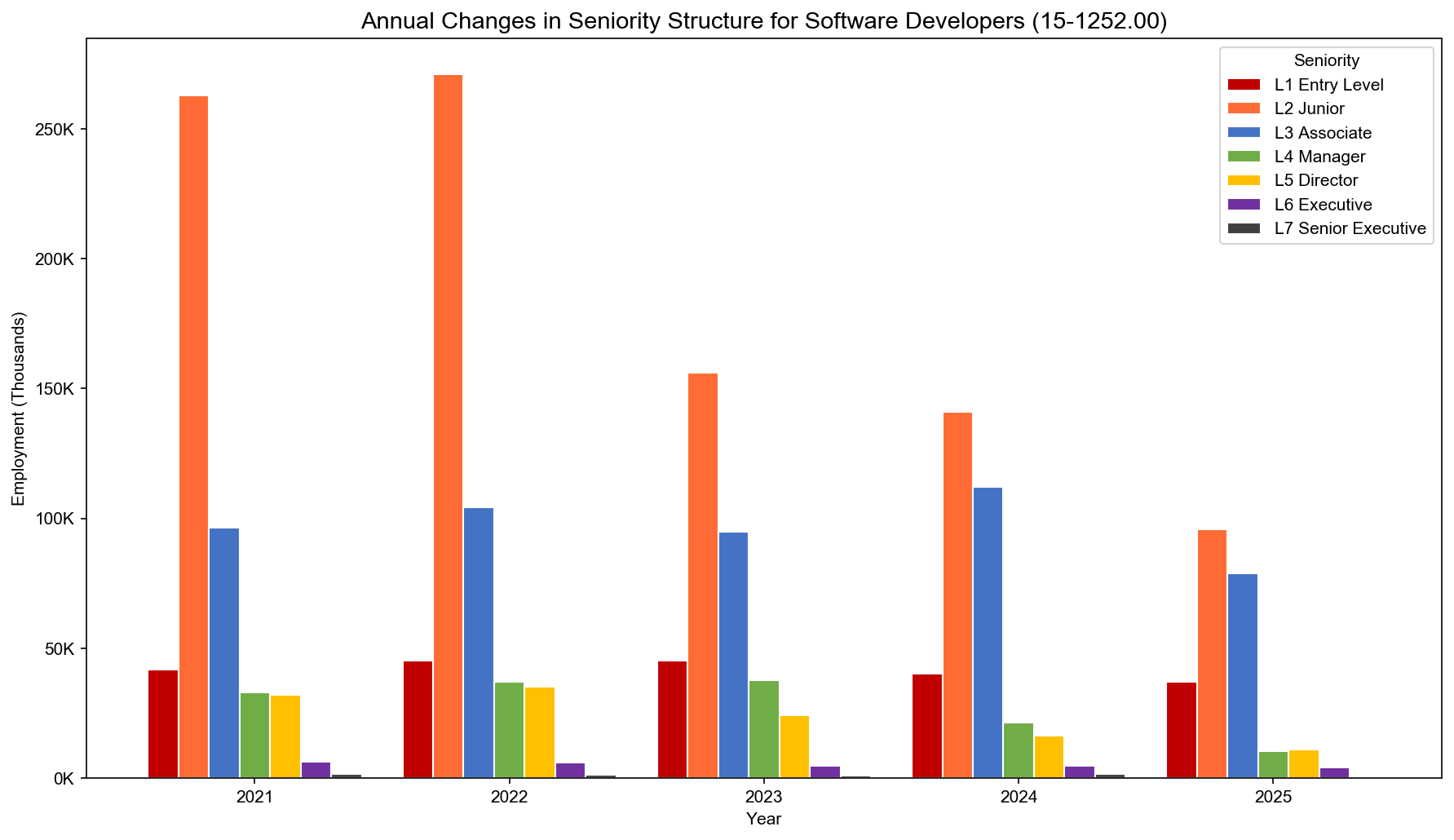
The result is clear: within software development positions, what truly declined significantly is L2, not the entire junior category. Specifically:
- L1: 1.2M → 1.1M, minor fluctuation
- L2: 2.8M → 1.45M, nearly halved
- L3+: 4.4M → 4.25M, essentially stable
In other words, at a coarse level it looks like junior positions are declining; but when broken apart, L1 shows no significant drop — it’s specifically L2 that’s dragging junior positions down.
This query is extremely complex. It requires aggregating data across different occupations, 7 seniority levels, and 5 years — a very demanding fine-grained query. Thanks to NeuGBI’s sampling methodology, we can quickly see the data trends and continue drilling down.
At this point, we’ve truly gotten to the bottom of this question: “junior positions are contracting” isn’t accurate enough. At least within software development, junior-level positions declined more significantly than entry-level.
Conclusion
Looking back, the entire replication was conducted autonomously by NeuGBI: on 60GB / 300 million U.S. employment records, it produced the same primary conclusion as the Harvard paper — junior positions declined more significantly while senior positions remained relatively stable — and on software development roles specifically, it uncovered a finer conclusion not present in the paper: what truly declined dramatically is junior-level positions, while entry-level and other levels remained relatively stable.
NeuGBI’s value here is also straightforward: it lets us first validate a coarse conclusion, then continue drilling down. One path examines overall employment, computer-related occupations, and major states; another returns to junior vs. senior positions, then drills into specific occupations and seniority levels. For questions where you don’t know where the answer is hiding at the outset, this step-by-step querying capability matters more than any single query.
References
- Harvard Business School Paper: Generative AI as Seniority-Biased Technological Change
- NeuGBI Theory Paper: A Hypergraph-Based Framework for Exploratory Business Intelligence
- NeuG Graph Database: https://github.com/alibaba/neug
- NeuGBI Demo: https://github.com/shunyangli/neugbi-demo