Feeding Code Repositories into LLM Wiki: 6x Token Savings in One Knowledge Build
 Andrej Karpathy’s LLM Wiki reshapes the knowledge-base paradigm: no chunking, no vector index. The LLM itself handles create / read / update / delete on the knowledge, and the wiki evolves dynamically with use.
Andrej Karpathy’s LLM Wiki reshapes the knowledge-base paradigm: no chunking, no vector index. The LLM itself handles create / read / update / delete on the knowledge, and the wiki evolves dynamically with use.
If vector-retrieval knowledge bases are the “interpreter” of knowledge, LLM Wiki is the “compiler.” Raw sources are not re-read on every query — they are compiled into concise wiki summaries, and the LLM answers from those summaries whenever they suffice.
Karpathy’s proposal collected millions of views and thousands of GitHub stars in weeks, sparking a wave of reproductions. But almost every reproduction stops at textual data — papers, technical docs, study notes. Our day-to-day workflow involves frequent competitor-code surveys and architectural comparisons, which prompted a different question: what if we feed the code repository itself into the wiki?
1. Repository-Aware Knowledge Management
Document-level reproductions can ingest an entire file into the context window and let the LLM extract, summarize, and link. Code repositories break this assumption — context blows up, knowledge density is high, and structures are hierarchical. We had to redesign the pipeline to handle code.
1.1 Three-Layer Directory Structure
We keep the canonical LLM Wiki layout — raw / wiki / schema — but each layer carries different semantics when the source is code.
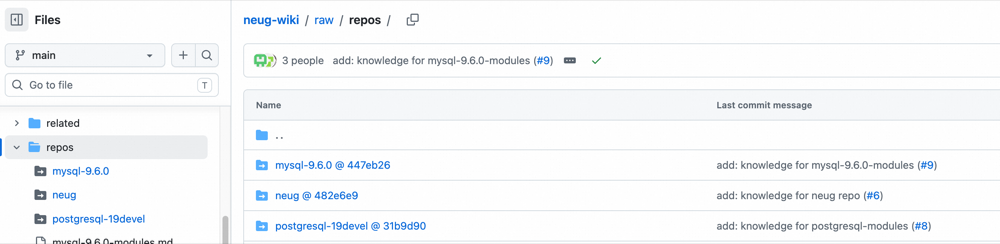
raw Directory
Most LLM Wiki implementations store original files in raw for answer authenticity. That works for plain text. It does not work for code: repositories are large and change constantly. For reference, the three databases we benchmarked weigh in at MySQL 6.36 GB · PostgreSQL 958 MB · NeuG 38 MB — well past what we want to drag around inside a knowledge base.
Our solution: use Git submodules. A submodule is just a pointer to a specific branch of a specific repository — the code is downloaded only when the LLM explicitly needs to read the source. Submodules also give incremental updates for free: a git diff between two branches tells us exactly which wiki entries need refreshing, so we never re-ingest the entire repo.
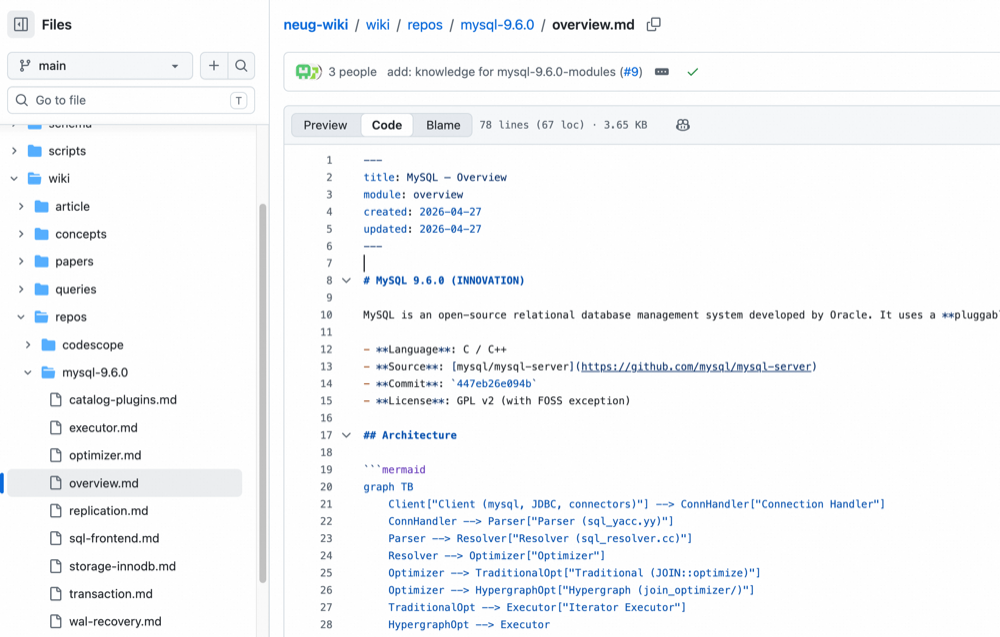
wiki Directory
Code repositories are too large to be summarized into a single wiki page. We partition the codebase into modules, and each module gets its own wiki page describing its function. These pages mirror the style of text-derived wikis — abstract, tags, dense reference links — so users can locate facts quickly and the LLM has fewer chances to hallucinate.
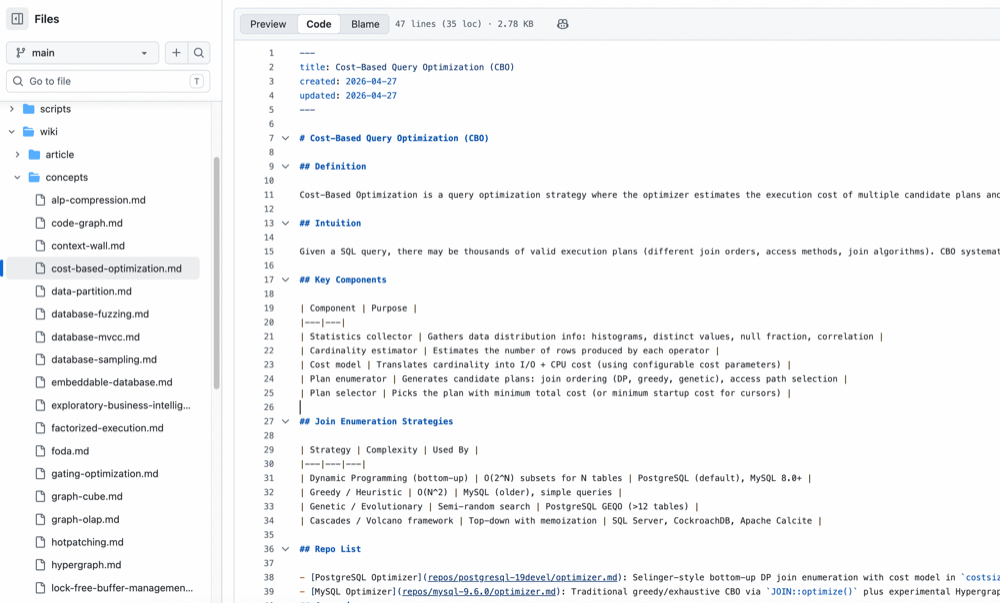
Beyond modules, individual code components can also link to concept pages. PostgreSQL and MySQL both implement cost-based optimization; during ingestion, the LLM updates the shared concept page with content from both repositories, forming cross-repository comparisons and associations naturally.
schema Directory
The schema directory holds the rules the LLM uses to manage the wiki. Because code repositories have their own quirks around storage, extraction, and querying, we wrote a dedicated prompt set to standardize the pipeline — covered in the next section.
1.2 Knowledge Ingestion
LLM Wiki defines three core operations: Ingest, Query, and Linter. Query and Linter reuse the existing wiki as-is, so the real challenge is producing accurate wikis during Ingest.
A code repository will not fit into the context window the way a plain document does. We surveyed tools like DeepWiki and RepoWiki, then adopted a two-stage generation strategy:
- Architecture phase. The LLM scans descriptive metadata — README, top-level docs, directory tree, build/config scripts — to form a high-level understanding of the project. It partitions the repository into modules and creates a placeholder wiki page per module. This stage only fixes module names — no content yet.
- Detail phase. With the partitioning settled, the LLM reads the actual code for each module and fills in the detailed wiki content.
This separation lets the LLM autonomously decide how many wiki pages a repository needs based on scale and complexity, keeping each module’s code small enough to fit context. It also gives the user a cheap checkpoint: inspect the module partitioning before paying for the expensive detail phase.
2. Aligning Concepts and Modules
2.1 Concept Alignment
Extracting concepts from raw documents is the heart of building a knowledge base — shared concepts are what turn isolated documents into a graph.
Before LLMs this was hard: “data modification” and “data update” mean the same thing; “quantization trading” and “quantization compression” do not. Modern LLMs, with proper context, can do concept alignment almost perfectly. Across the LLM Wiki implementations we surveyed, the pattern boils down to three rules:
Read every existing concept already in the LLM Wiki.
Summarize 3–5 concepts from the new document.
Allow at most one new concept to be introduced.
Compared to free-form summarization, this disciplines the LLM into matching and updating existing concepts instead of inventing new ones — which is what keeps the wiki from fragmenting into noise.
2.2 Module Alignment
Inspired by the concept-alignment trick, we inject the wiki directories of previously-ingested repositories into the context before parsing a new one. The LLM is told to reference existing module titles when partitioning the new repository.
This turns module partitioning from “fill in the blank” into “multiple choice”. Instead of brainstorming module names, the LLM reverse-checks whether each known module exists in the new codebase, and only invents a new label when the functionality genuinely has no analogue.
2.3 Experimental Comparison
We partitioned PostgreSQL twice — once on its own, once with reference to MySQL and NeuG wikis.
| Independent Partitioning | Aligned Partitioning (with Reference) |
|---|---|
| Processing Pipeline | SQL Frontend Optimizer Execution |
| Storage | Storage |
| Transaction | Transaction WAL Recovery |
| Replication | Replication |
| Utility & Client Tools | Utilities |
| Build System | — |
Neither result is strictly “wrong” on content. But critical architectural pieces like the Optimizer and WAL rarely have explicit textual descriptions and account for only a small fraction of the file count, so they get drowned out in independent extraction.
In database engineering, Optimizer and WAL are pivotal — surrounded by theory, papers, and operational lore. Surfacing them as separate modules is clearly better. Conversely, support pieces like the Build System are less central and lack analogues in other databases, so dropping them from the wiki is a reasonable trade.
3. Team Collaboration
Karpathy’s framing — and most reproductions — treat LLM Wiki as a personal knowledge base: open an LLM tool inside the wiki directory and chat. That leaves two gaps: invoking the wiki from inside other projects, and sharing the wiki across users.
3.1 Cross-Project Sharing
To let any project talk to the wiki, we packaged it as a skill. We renamed AGENT.md to SKILL.md and dropped the whole folder under .agents/skills/llm-wiki. Any project can now invoke the wiki through the standard skill mechanism:
paper-101.pdf/neug-wiki add this paper to the wiki.
3.2 Cross-User Sharing
For multi-user access we host the LLM Wiki on GitHub. Setup is one command: cd .agents/skills/llm-wiki && git clone …. Coding tools parse the skill on clone.
GitHub’s read path is easy — users pull the whole wiki and the LLM reads it locally. The write path is where it gets interesting: shared editing brings concurrency conflicts. We resolve this by requiring every update — almost always an ingest — to go through a Pull Request. The full workflow is orchestrated inside SKILL.md so users only confirm at the web interface; everything else is automated.
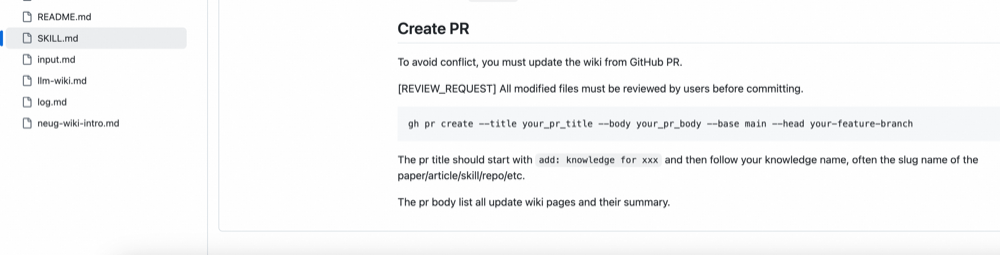
3.3 Linter and CI Checks
Hosting on GitHub lets us encode wiki rules into the CI pipeline. We split rules into two kinds:
-
Mandatory rules — must hold on every update; violations block the merge. Examples: link paths must resolve, the
rawdirectory is append-only, file sizes are capped. One check rejects accidentally-uploadedSKILL.mdfiles because they would confuse other skills’ registration.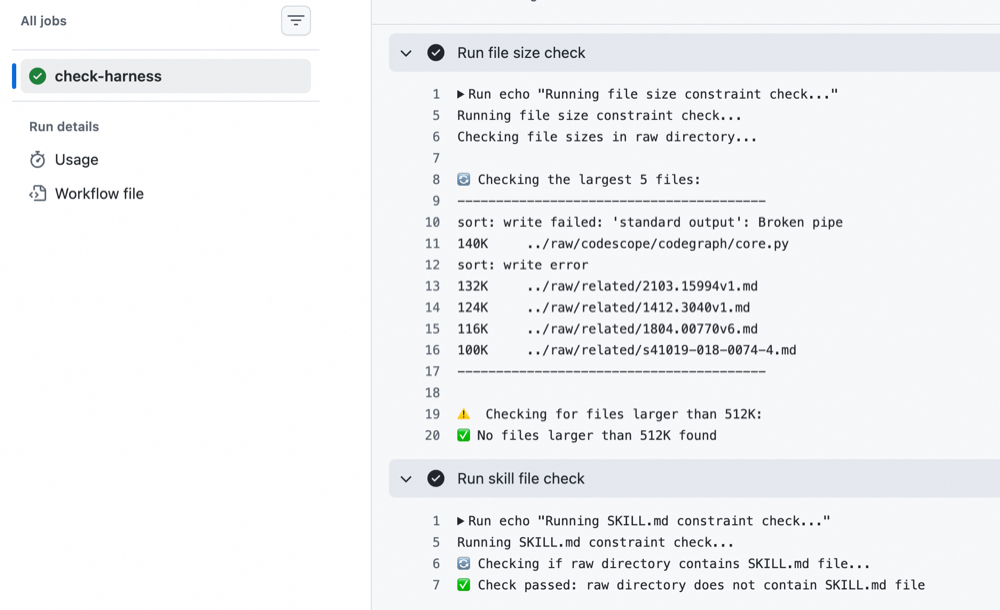
-
Advisory rules — judgment calls a rigid rule cannot make. These get surfaced as PR comments for the user to confirm. A healthy PR uploads raw data, summarizes it, extracts concepts, and updates wikis. If something is off — say one raw file produced two wikis — the system flags it and asks for confirmation.
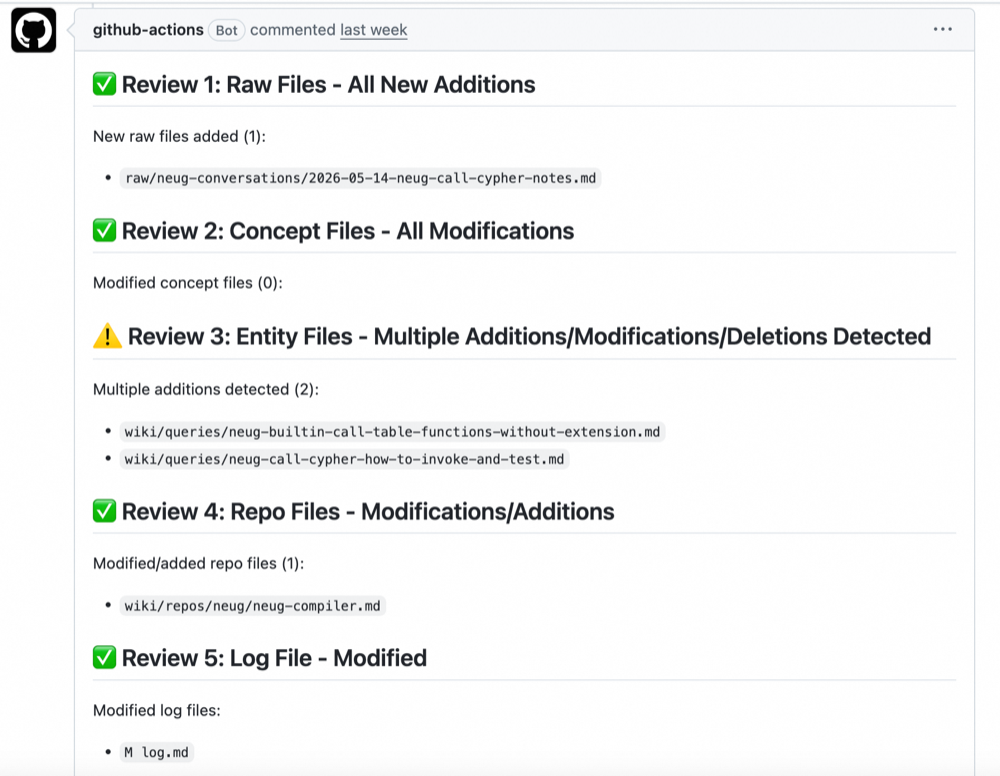
4. Case Study: 6x Token Savings on a Single Query
Competitive-implementation comparison is one of the most common queries we run during technology selection. We selected two well-known databases — MySQL and PostgreSQL — and our team’s open-source NeuG, then asked the LLM Wiki to compare their transaction-management designs side by side.
4.1 Data Preparation
All three repositories were ingested through the full pipeline. Two arms:
- Experimental — the LLM answers from the wiki.
- Control — the LLM answers by reading the raw code.
4.2 Response Quality
Answers vary in wording; we compare the structural outlines.
Experimental (with wiki):
# Comparative Analysis Report on Transaction Strategies of Three Major Databases
## I. Overall Architecture Overview
## II. MVCC Implementation Comparison
## III. Lock Mechanism Comparison
## IV. Isolation Level Comparison
## V. WAL and Crash Recovery
## VI. Garbage Collection / Space Reclamation
## VII. Featured Mechanisms
## VIII. Summary
Control (raw code only):
# Report on Transaction Strategies of Three Databases
## I. Transaction Architecture Overview
## II. Transaction Isolation Levels
## III. MVCC Implementation Details
## IV. Concurrency Control Mechanisms
## V. WAL (Write-Ahead Logging) Mechanism
## VI. Transaction Commit Process
## VII. Two-Phase Commit (XA / 2PC) and Distributed Transactions
## VIII. Savepoints and Sub-transactions
## IX. Deadlock Detection
## X. Overall Assessment
Both arms surfaced the key modules — MVCC, concurrency control, isolation levels, WAL. The control arm, with code in context, leans toward implementation-level details. The experimental arm, reading the wiki, leans toward architectural framing — but answers the question completely without ever touching the source. From a “technical summary” standpoint, both responses were high-quality.
4.3 Resource Overhead
Since multi-turn context inflates raw token counts and pricing varies by token type, we use final billed credits as the apples-to-apples baseline. Both runs used DeepSeek-V4-Pro with cleared memory.
| Group | Context Length | Credit Cost | Money Cost | Execution Time |
|---|---|---|---|---|
| Experimental | 30k | 3.11 | $0.04 | 3 min |
| Control | 110k | 18.44 | $0.27 | 13 min |
| Improvement | 3.66x | 5.92x | 6.75x | 4.33x |
Using the wiki cut token consumption to roughly 1/6. Since generation speed is roughly fixed, lower token consumption translates directly into >4x faster execution. A token-efficient query saves money — and it saves time.
5. Conclusion and Outlook
This LLM Wiki + Code practice is our first attempt at extending wiki-style data management into multi-modal territory. We believe an LLM-managed wiki, like the LLM itself, should be capable of ingesting and emitting data in arbitrary formats. This management style also breaks the boundary between data sources: with the LLM’s understanding doing the bridging, all data — text, code, and beyond — can live in a single unified knowledge base.
Links: NeuG · LLM Wiki (Karpathy)